Учимся парсить сайты на C#: часть 1
Данная статья первая из цикла "Парсим сайты на C#". В ней мы научимся непосредственно подключаться к выбранному серверу, скачивать страничку, разбирать её исходный код, а также выводить на экран первоначальный результат. Эта программа только для тестов – для реальной работы я рекомендую использовать готовые библиотеки. Однако даже без библиотек, встроенными средствами NET несложно сделать настоящее приложение - парсер для сайтов самостоятельно.
Итак, начнем мы с того, что научимся получать страничку. В данном случае пациентом выступает рейтинг топ лиру, конкретно страница с адресом "https://www.liveinternet.ru/?upread.ru" - именно в этом ареале в настоящий момент обитает мой блог. Эту страницу мы скачиваем, ищем на ней адрес "upread.ru" (парсим) и выводим место, на котором данный сайт находится. На выходе будет примерно такая картинка.
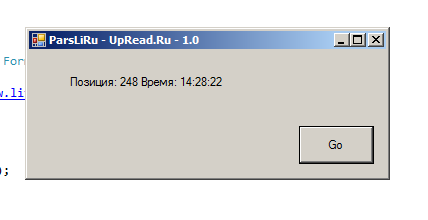
А вот и сам код программы:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Text.RegularExpressions;
namespace ParsLiRu
{
public partial class Form1 : Form
{
string url = "https://www.liveinternet.ru/?upread.ru";
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
backgroundWorker1.RunWorkerAsync();
}
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
using (WebClient client = new WebClient())
{
client.Encoding = System.Text.Encoding.UTF8;
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls12 | SecurityProtocolType.Tls11 | SecurityProtocolType.Tls;
var htmlData = client.DownloadData(url);
string htmlCode = Encoding.UTF8.GetString(htmlData);
var parts1 = Regex.Split(htmlCode, "nick=upread.ru\">");
var parts2 = Regex.Split(parts1[1], " ");
int numberPosition = Convert.ToInt32(Regex.Replace(parts2[0], @"[^\d]+", ""));
this.Invoke(new MethodInvoker(delegate {
label1.Text = Convert.ToString("Позиция: " + numberPosition + " Время: " + System.DateTime.Now.ToLongTimeString());
}));
}
}
}
}
Несколько комментариев по коду выше. В строке 32 создаем WebClient; далее 34 - здесь задается кодировка скачиваемой страницы. В строке 35 включаем поддержку защищенного протокола (https). 37-38 – получаем данные страницы и конвертим их в string, учитывая кодировку.
Сам разбор страницы происходит в строках 40-42 – с помощью регулярных выражений убираем все до вхождения подстроки upread.ru, далее получаем второй элемент массива (сплит по коду пробела) и в конце опять же с помощью регулярок оставляем только число.
Вот так мы создали простейший парсер страниц на си шарп. Повторюсь, что для реальной работы лучше использовать готовые библиотеки. Вот например, Как парсить сайты с помощью CsQuery.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты