Как парсить сайты с помощью CsQuery
Удобная и бесплатная библиотека CsQuery дает отличную возможность написать свой парсер для сайтов. Гибкий и шустрый. Давайте на примере рассмотрим, как ей пользоваться. В этой статье я расскажу основы, а также помогу избежать ошибок. Если же вам требуется парсер на заказ, то пишите мне – сделаем вместе. Не бесплатно, но недорого.
Немного теории
CsQuery использует селекторы CSS и jQuery, которые дают возможность очень просто получить доступ и манипулировать HTML. Можно использовать его в веб-проектах для постобработки на HTML-страницах перед их подачей, для веб-скрейпинга, разбора шаблонов и т. д., а не только парсинга сайтов.
CsQuery создаст идентичный DOM из того же источника, что и любой браузер на основе Gecko. CsQuery реализует все селекторы CSS2 и CSS3 и фильтры, а также комплексную модель DOM. Вы можете использовать все те же методы jQuery (и элемент DOM), с которыми вы знакомы, для перемещения и управления DOM.
Механизм выбора CSS полностью индексирует каждый документ по имени тега, идентификатору, классу и атрибуту. Индекс является субсекто-дееспособным, что означает, что сложные селекторы все еще смогут воспользоваться индексом (для любой части индексированного селектора). Производительность селекторов по сравнению с другими существующими на C# в HTML парсинг библиотек порядков быстрее.
Более того, весь тестовый набор из Sizzle (jQuery CSS selector engine) и jQuery (1.6.2) был перенесен из Javascript в C# для этого проекта. Почти все, что вам нужно, это в объект CQ, который предназначен для работы как объект jQuery.
Подключение CsQuery к Visual Studio
Итак, для начала качаем проект CsQuery. Из множества файлов в нем нам потребуется только библиотека CsQuery.dll, находящаяся в папке distribution. Подключаем её как обычно к проекту в Visual Studio – добавляем ссылку:
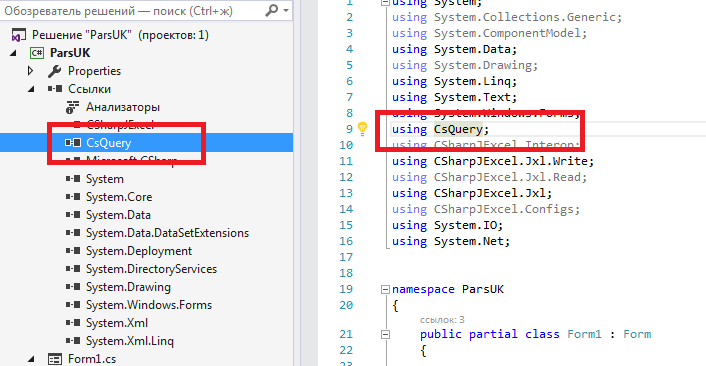
И теперь можно использовать пространство имен
using CsQuery;Отлично. Но теперь давайте посмотрим на сайт, с которого требуется собрать информацию, спарсить данные – так называемый сайт-донор.
Разбор сайта
Чтобы что-то вытащить с сайта, надо понять его структуру. Для примера возьмем сайт mingkh.ru – предположим, что нам надо вытащить оттуда адреса и телефоны управляющих компаний. Очень часто помимо непосредственного разбора страницы компании, с которой надо взять информацию, требуется еще собрать и адреса страниц этих самых компаний. В нашем случае это делается просто.
Есть страница со всеми компаниями. Если мы посмотрим исходный код её, то обнаружим закономерность:
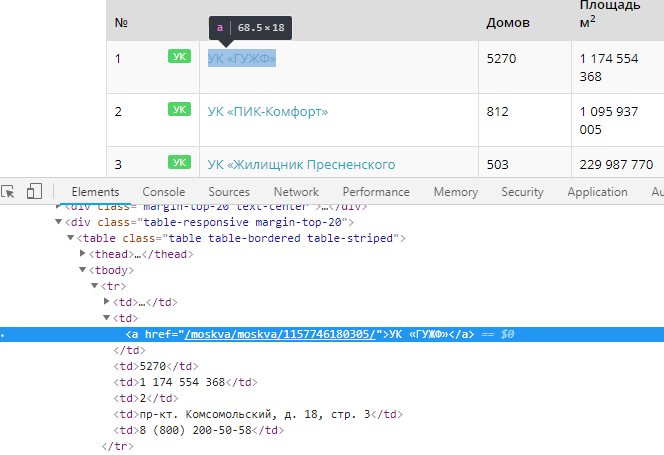
Каждая ссылка в таблице класса table-striped ведет на страницу компании, так что собрав все эти ссылки, мы сможем получить массив адресов страниц.
Сбор адресов страниц
Возвращаемся к нашему проекту в визуал студии на C# и пишем такой код в обработчике кнопки:
CQ dom = CQ.CreateFromUrl("http://mingkh.ru/rating/moskva/moskva/");
foreach (IDomObject obj in dom.Find(".table-striped a"))
{
if (obj.GetAttribute("href") != "")
{
chet++;
mass[chet, 0] = "http://mingkh.ru" + obj.GetAttribute("href");
textBox1.Text += mass[chet, 0] + System.Environment.NewLine;
}
}
Давайте рассмотрим его подробнее. В первой строке создаем дерево элементов страницы. Далее проходим циклом по всем ссылкам в таблице с классом table-striped. Если у объекта ссылка не пустая, то заносим в массив и выводим его в текстбокс. Отлично, теперь мы имеем список адресов.
Карточка компании
Пришло время поработать с карточкой компании. Здесь тоже все просто. Необходимая нам информация находится в тегах dd:
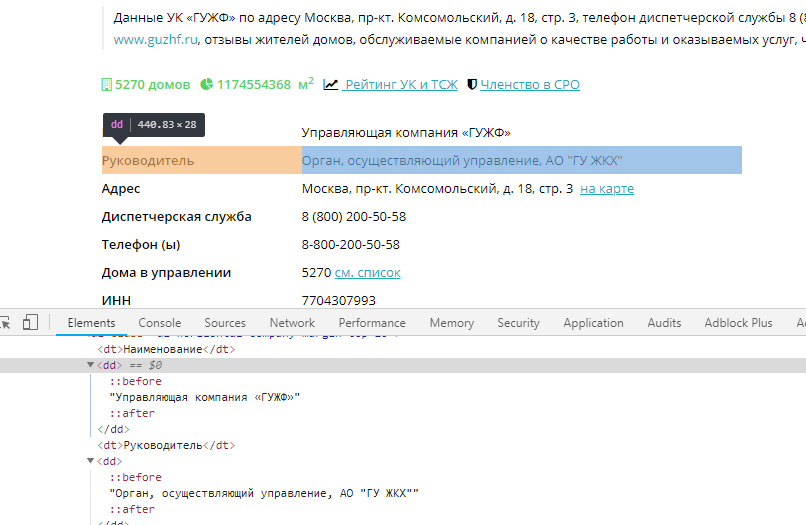
Получить её можно вот так:
CQ dom = CQ.CreateFromUrl("http://mingkh.ru/moskva/moskva/1157746180305/");
foreach (IDomObject obj in dom.Find("dd"))
{
if (obj.TextContent != "")
{
textBox1.Text += = obj.TextContent;
}
}
Чтобы выбрать адреса и телефоны, можно пойти двумя путями. Если пункты в карточке компании не меняются и у всех одинаковы, то просто взять элемент по порядку. Например, адрес – это третий тег dd, то есть выбирается вот так:
dom.Find("dd").Eq(3)
А если вы не уверены, что какой-то пункт может быть пропущен, то для каждой страницы можно составить таблицу соответствий, инициализировать два массива. Первый заполнить названиями пунктов, а второй – содержимым.
В следующих статьях мы разберем некоторые хитрости парсинга. При обработке больших объемов информации требуется работать не так в лоб. Если вам требуется помощь, то смело пишите мне. За небольшую плату я с удовольствием помогу вам разобраться в вопросах парсинга сайтов на C#.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты