Пример парсинга сайта с помощью Java
Не так давно работал над одним интересным заказом. Если вкратце, то необходимо было написать mp3 плеер на java, который бы мог не только воспроизводить музыку, писать в плейлисты (что делают обычные плееры), но и сам искать (и качать) песни в интернете. В этой статье мы научимся парсить сайты с помощью Java.
Для начала на потребуется сторонняя библиотека – не будем же мы разбирать страницу с помощью регулярных выражений, верно? Я выбрал jsoup Java HTML Parser Нам нужен jar-ник – на время написания статьи последний был 1.11.3. Подключаем его к нашему проекту, а в основном файле подключаем уже пространства имен:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements;В качестве подопытного кролика выбран сайт mp3party.net – там все просто, поиск идет с помощью get запросов, нет защиты – в общем, идеальный пациент. Создаем кнопку и в обработчик её помещаем следующий код:
Button btnFind = new Button();
btnFind.setText("Найти песню");
btnFind.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
//получаем строку запроса
String query = textBox.getText();
name = "";
lbFind.setText("Подождите, идет поиск....");
//парсим страницу запроса
try {
doc = Jsoup.connect("http://mp3party.net/search?q="+query).get();
} catch (IOException ex) {
Logger.getLogger(FindListen.class.getName()).log(Level.SEVERE, null, ex);
}
Elements newsHeadlines = doc.select(".song-item a");
int i = -1;
for (Element headline : newsHeadlines) {
i++;
if (i==0) {
sst = headline.absUrl("href");
name = headline.ownText();
}
}
if (name!="") {
lbFind.setText("Найдено: "+name);
btnDounload.setVisible(true);
muss = "mp3/"+name+".mp3";
}
else {
lbFind.setText("Ничего не найдено!");
}
}
});
Обратите внимание, что помимо кнопки в окне должно быть как минимум два элемента: текстбокс, откуда берется то, что надо искать (название песни) и метка (lbFind), в которую мы выводим полученный результат.
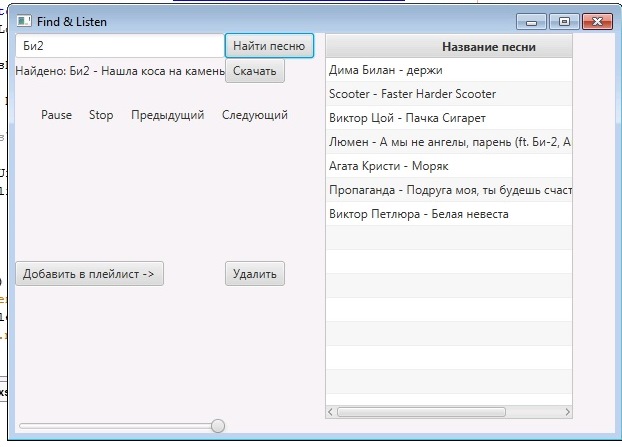
По сути дела здесь мы просто выполняем get-запрос к сайту и в ответе на странице ищем то, что идет после .song-item a. Затем в цикле все перебираем и запоминаем первый результат. В итоге мы получаем два результата: адрес страницы с песней (sst) и её название. Теперь уже можно парсить саму страницу с музыкой и затем её качать. Но это уже в следующей статье.
Если вам что-то непонятно, требуется помощь по Java, то вы можете написать мне на почту up777up@yandex.ru – за разумную плату я вам с удовольствием помогу.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты