План парсинга одного сайта
И снова заказ на парсинг – на этот раз крупного государственного портала. Требуется написать сервис на php, который будет получать список страниц (ссылок) по некоторым параметрам и потом граббить эти страницы. Давайте распишем общий план парсинга на php.
Получение ссылок
У нас нет списка страниц для граббинга, их необходимо получить, применяя некие параметры фильтрации. Для того, чтобы получить их, надо отправить POST-запрос с помощью php (curl). В этой статье мы уже проделывали что-то подобное, но нелишним будет и повторить:
$url = 'http://куда_идет_запрос ';
$fields = array(
'Page' => $page,
'Count' => 25,
'Courts' => $Courts,
'DateFrom' => $DateFrom,
'DateTo' => $DateTo,
'Sides' => array(
),
'Judges' => array(
),
'CaseNumbers' => array(
),
'CaseType' => $CaseType,
'WithVKSInstances' => false
);
$fields_string = http_build_query($fields);
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL, $url);
curl_setopt($ch,CURLOPT_POST, 1);
curl_setopt($ch,CURLOPT_POSTFIELDS, $fields_string);
curl_setopt($ch,CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION, true);
$result = curl_exec($ch);
echo $result;
curl_close($ch);
Откуда мы берем поля, которые отправляются в запросе? Из отладчика любого браузера:
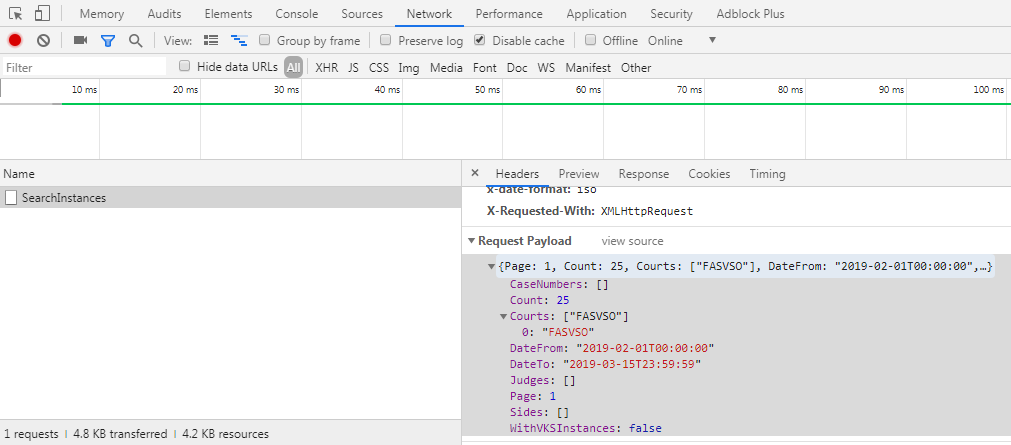
Обратите внимание, что мы отправляем массивы – здесь некоторые пустые. Иногда мы просто не знаем, будут ли элементы в массивах, сколько их, в каком порядке и т.д. К счастью, php дает возможность инициализировать массивы без обозначения размера, а потом добавлять в них элемент по мере необходимости без указания индекса. Получается что-то вроде стека:
$Courts = array(); array_push($Courts, "SPB");Ну вот получили мы страницу со ссылкам (в коде выше вывели её в браузер), но как достать оттуда эти самые ссылки? Можно воспользоваться любой php-библиотекой для парсинга html, лично я чаще всего использую самую простую – simple html dom. Все, что требуется – это скачать и подключить файл (не забудьте распаковать его), а затем находить элементы согласно правилам. Например, вот так:
include_once('simple_html_dom.php');
$html = str_get_html($result);
foreach($html->find('.instantion-name a') as $element) {
$adres = $element->href;
//что-то делаем с полученной ссылкой
}
Похоже на CsQuery, не правда ли? Ничего удивительного, очень удобно разбирать html-структуру с помощью селекторов. Кстати, если у вас уже есть список страниц, то вам и не нужен будет курл – он требуется только для создания POST-запроса и получения ответа, тогда сразу можно будет получать html из удаленного адреса:
$html = file_get_html('адрес_страницы');

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты