Быстрое введение в элементы программирования
Данный материал рассчитан на не программистов, на людей, которым необходимо быстро разобраться и получить представление о программировании как системе сущностей. Иными словами для новичков, которые просто хотят понять, что это такое без общих фраз, а с примерами.
Несмотря на различия в обозначениях, современные компьютерные языки обеспечивают многие из тех же структур программирования. К ним относятся основные структуры управления и структуры данных. Первые предоставляют средства для выражения алгоритмов, а вторые - способы организации информации.
Структуры управления
Программы, написанные на процедурных языках, наиболее распространенных, они похожи на рецепты, содержащие списки ингредиентов и пошаговые инструкции по их использованию. Тремя основными структурами управления практически в каждом процедурном языке являются:
- Последовательность — смешайте жидкие ингредиенты, а затем добавьте сухие.
- Условно — если помидоры свежие, то тушите их на медленном огне, но если консервированные, пропустите этот шаг.
- Повторный — взбейте яичные белки до загустевания
Эти структуры управления могут быть объединены. Последовательность может содержать несколько циклов; цикл может содержать вложенный в него цикл, или каждая из двух ветвей условного может содержать последовательности с циклами и большим количеством условных. В “псевдокоде”, используемом в этой статье, “ * ” указывает на умножение, а “←” используется для присвоения значений переменным. В следующем фрагменте программирования используется структура IF-THEN для нахождения одного корня квадратного уравнения с использованием квадратичной формулы:
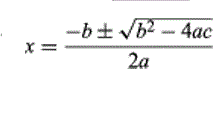
Квадратичная формула предполагает, что a не равно нулю и что дискриминант (часть в знаке квадратного корня) не является отрицательным (для получения действительного корня числа). Условные условия проверяют эти предположения:
IF a = 0 THEN ROOT ← −c/b ELSE DISCRIMINANT ← b*b − 4*a*c IF DISCRIMINANT ≥ 0 THEN ROOT ← (−b + SQUARE_ROOT(DISCRIMINANT))/2*a ENDIF ENDIFФункция SQUARE_ROOT, используемая в приведенном выше фрагменте, является примером подпрограммы (также называемой процедурой, подпрограммой или функцией). Подпрограмма подобна рецепту соуса, который дается один раз и используется как часть многих других рецептов. Подпрограммы принимают входные данные (необходимое количество) и выдают результаты (соус).
Обычно используемые подпрограммы, как правило, находятся в коллекции или библиотеке, снабженной языком. Подпрограммы могут вызывать другие подпрограммы в своих определениях, как показано в следующей процедуре (где ABS-функция абсолютного значения). SQUARE_ROOT реализуется с помощью цикла WHILE (неопределенный), который обеспечивает хорошее приближение квадратного корня из действительных чисел, если только x не очень мал или очень велик. Подпрограмма записывается путем объявления ее имени, типа входных данных и выходных данных:
FUNCTION SQUARE_ROOT(REAL x) RETURNS REAL ROOT ← 1.0 WHILE ABS(ROOT*ROOT − x) ≥ 0.000001 AND WHILE ROOT ← (x/ROOT + ROOT)/2 RETURN ROOTПодпрограммы могут разбить проблему на более мелкие, более поддающиеся решению подзадачи. Иногда проблему можно решить, сведя ее к подзадаче, которая является уменьшенной версией оригинала. В этом случае процедура известна как рекурсивная подпрограмма, потому что она решает проблему, многократно вызывая саму себя. Например, факториальная функция в математике (n! = n∙(n−1)⋯3∙2∙1—т. е. произведение первых n целых чисел), может быть запрограммировано как рекурсивная процедура:
FUNCTION FACTORIAL(INTEGER n) RETURNS INTEGER IF n = 0 THEN RETURN 1 ELSE RETURN n * FACTORIAL(n−1)Преимущество рекурсии заключается в том, что она часто является простым повторением точного определения, которое позволяет избежать бухгалтерских деталей итеративного решения.
На уровне машинного языка циклы и условные обозначения реализуются с помощью инструкций ветвления, которые говорят “перейти к” новой точке в программе. Оператор “goto” на языках более высокого уровня выражает ту же операцию, но используется редко, поскольку людям трудно следить за “потоком” программы. Некоторые языки, такие как Java и Ada, не имеют этого оператора.
Структуры данных
В то время как структуры управления организуют алгоритмы, структуры данных организуют информацию. В частности, структуры данных определяют типы данных и, следовательно, какие операции с ними могут выполняться, устраняя при этом необходимость для программиста отслеживать адреса памяти. Простые структуры данных включают целые числа, действительные числа, логические значения (true/false) и символы или символьные строки. Составные структуры данных формируются путем объединения одного или нескольких типов данных.
Наиболее важными составными структурами данных являются массив, однородный набор данных, и запись, гетерогенная коллекция. Массив может представлять собой вектор чисел, список строк или набор векторов (массив массивов или математическую матрицу). В записи может храниться информация о сотруднике — имя, должность и зарплата. Массив записей, такой как таблица сотрудников, представляет собой набор элементов, каждый из которых неоднороден. И наоборот, запись может содержать вектор, то есть массив.
Компоненты записи или поля выбираются по имени; например, E.SALARYможет представлять поле зарплаты записи E. Элемент массива выбирается по его позиции или индексу; A[10] - это элемент в позиции 10 в массиве A. Таким образом, цикл FOR (определенная итерация) может проходить через массив с ограничениями индекса (ОТ ПЕРВОГО до ПОСЛЕДНЕГО в следующем примере), чтобы суммировать его элементы:
FOR i ← FIRST TO LAST SUM ← SUM + A[i]Массивы и записи имеют фиксированные размеры. Структуры, которые могут расти, создаются с помощью динамического распределения, которое обеспечивает новое хранилище по мере необходимости. Эти структуры данных содержат компоненты, каждый из которых содержит данные и ссылки на другие компоненты (в машинном выражении, их адреса). Такие самореферентные структуры имеют рекурсивные определения.
Например, двоичное дерево (бинарное дерево) либо пусто, либо содержит корневой компонент с данными и левым и правым “дочерними” бинтриями. Такие деревья привязок эффективно реализуют таблицы информации. Подпрограммы для работы с ними естественно рекурсивны; следующая процедура выводит все элементы дерева (каждый из которых является корнем некоторого поддерева):
PROCEDURE TRAVERSE(ROOT: BINTREE) IF NOT(EMPTY(ROOT)) TRAVERSE(ROOT.LEFT) PRINT ROOT.DATA TRAVERSE(ROOT.RIGHT) ENDIFАбстрактные типы данных (ADT) важны для крупномасштабного программирования. Они упаковывают структуры данных и операции с ними, скрывая внутренние детали. Например, таблица ADT предоставляет пользователям операции вставки и поиска, сохраняя при этом базовую структуру, будь то массив, список или двоичное дерево, невидимой. В объектно-ориентированных языках классы являются ADT, а объекты - их экземплярами.
В следующем примере объектно-ориентированного псевдокода предполагается, что существует СОПОСТАВИМОЕ дерево ADT и “суперкласс”, характеризующие данные, для которых выполняется операция сравнения (например, “ < ” для целых чисел). Он определяет новый ADT, ТАБЛИЦУ, которая скрывает свое представление данных и предоставляет операции, соответствующие таблицам. Этот класс определяется полиморфно в терминах параметра типа элемента СОПОСТАВИМОГО класса. Любой его экземпляр должен указывать этот тип, здесь класс с данными о сотрудниках (СОПОСТАВИМОЕ объявление означает, что PERS_REC должен предоставить операцию сравнения для сортировки записей). Детали реализации опущены.
CLASS TABLE OF <COMPARABLE T>
PRIVATE DATA: BINTREE OF <T>
PUBLIC INSERT(ITEM: T)
PUBLIC LOOKUP(ITEM: T) RETURNS BOOLEAN
END
CLASS PERS_REC: COMPARABLE
PRIVATE NAME: STRING
PRIVATE POSITION: {STAFF, SUPERVISOR, MANAGER}
PRIVATE SALARY: REAL
PUBLIC COMPARE (R: PERS_REC) RETURNS BOOLEAN
END
EMPLOYEES: TABLE <PERS_REC>
TABLE публикует только свои собственные операции; таким образом, если она изменена для использования массива или списка, а не дерева, программы, которые ее используют, не смогут обнаружить изменение. Это сокрытие информации имеет важное значение для управления сложностью в больших программах. Он делит их на небольшие части с “контрактами” между частями; здесь класс TABLE заключает контракты на выполнение операций поиска и вставки, а его пользователи заключают контракты на использование только тех операций, которые были опубликованы таким образом.
Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты