Урок 1. Введение в параллельное программирование C#
Это первая статья в серии статей, посвященных методам параллельного программирования, доступным на языке C# и платформе .NET framework версии 4.0. В первой части описаны некоторые понятия параллельного программирования.
Последовательный код
Проблема, с которой мы сталкиваемся как разработчики, заключается в том, что нас учили думать о программировании последовательным образом. Если мы продолжим программировать таким образом, наше программное обеспечение не будет использовать преимущества улучшений, доступных благодаря параллельной обработке. Стандартная программа .NET, которая не создает новые потоки, будет использовать только одно ядро. На современном оборудовании это может означать, что нам доступна только половина или четверть доступной вычислительной мощности. В будущем подобные программы могут использовать лишь крошечную часть процессора. Аналогичное программное обеспечение, которое полностью использует параллельное программирование, будет работать лучше и, вероятно, будет одобрено нашими пользователями.
До .NET 4.0 разработчики C# могли получить улучшенную производительность новых процессоров, создав многопоточное программное обеспечение. Часто этот тип программного обеспечения создает только несколько дополнительных потоков, чтобы ускорить процесс или позволить пользовательскому интерфейсу оставаться отзывчивым, пока выполняется фоновая задача. Если количество потоков увеличивается намного больше, чем количество ядер, накладные расходы могут привести к тому, что программа будет работать медленнее по всем направлениям. Если нет достаточного количества потоков, чтобы держать каждое ядро занятым, программа может работать хуже на некотором оборудовании. Вы можете проверить процессор в своем коде и соответственно создать новые потоки, но это может быть сложно.
С .NET 4.0 Microsoft представила новые инструменты, призванные упростить создание параллельного кода. Они устраняют некоторые, но не все сложности многопоточности. Они также позволяют одному и тому же коду работать на разных компьютерах с различным количеством ядер, используя преимущества всех доступных процессоров.
Декомпозиция
Параллельное программирование опирается на принцип декомпозиции. Это процесс разбиения программы, алгоритма или набора данных на разделы, которые могут быть обработаны независимо. Некоторые алгоритмы могут быть легко разложены, но другие, естественно, последовательны и не поддерживают параллелизм. Возможно, вам придется полностью заменить алгоритм, чтобы получить результат, который может быть лучше разложен, иначе последовательные части могут устранить преимущества параллелизма. Например, если у вас есть процедура, выполнение которой занимает десять минут, и алгоритм поддерживает легкую декомпозицию, выделение 25% работы каждому из четырех процессоров может сократить продолжительность до двух с половиной минут. Если 90% алгоритма должно обрабатываться последовательно, то десятиминутная задача может быть разделена между четырьмя ядрами, но одно ядро будет работать над ней девять минут, в то время как остальные ядра будут простаивать.
Существует два типа декомпозиции, оба из которых могут быть использованы в одном алгоритме. Это декомпозиция данных и декомпозиция задач.
Декомпозиция данных
Декомпозиция данных обычно применяется для больших задач обработки данных. Это процесс разбиения большого количества данных на несколько более мелких групп. Каждый из этих небольших блоков может быть обработан отдельным процессором или ядром параллельно. В конце процесса меньшие единицы данных могут быть рекомбинированы в один больший набор результатов.
Общая задача, которая может принести пользу от декомпозиции данных, - это обработка изображений. Цифровая фотография может содержать десять миллионов пикселей. Если мы применяем фильтр к такой фотографии, нам может потребоваться выполнить один и тот же расчет для каждого пикселя. Если мы используем один поток, мы должны ждать, пока все десять миллионов задач будут выполняться последовательно. Если мы сможем распределить нагрузку на четыре ядра процессора, то время обработки может сократиться в четыре раза.
Декомпозиция задач
Декомпозиция задач, как правило, более сложна, чем декомпозиция данных, и ее труднее достичь. Вместо того чтобы искать большие наборы данных для разбиения, мы смотрим на используемые алгоритмы и пытаемся разбить их на более мелкие задачи, которые могут выполняться параллельно. В некоторых случаях алгоритмы строятся из блоков кода, которые тесно зависят друг от друга, что делает невозможным разделение более мелких задач. Эти алгоритмы должны быть полностью заменены, чтобы получить преимущество параллельной обработки.
Например, представьте себе, что у нас есть метод, который извлекает ряд наборов данных из различных источников, включая веб-службы, базы данных или файлы. Каждый набор данных требует некоторой предварительной обработки, прежде чем все они будут объединены и обработаны вместе для получения результата. Если части метода сбора данных независимы друг от друга, мы могли бы создать задачи для каждой из них, которые могли бы выполняться параллельно. Как только все параллельные задачи будут выполнены, мы сможем объединить наборы данных и получить окончательные результаты. Возможно даже, что эта конечная задача выиграет от декомпозиции данных.
Общие проблемы параллельного программирования
Общие проблемы, возникающие при разработке параллельного кода, такие же, как и при использовании нескольких потоков. Некоторые из этих проблем уменьшаются классами параллелизма .NET framework, но они не устраняются полностью, поэтому заслуживают упоминания. Терминология будет использована позже в учебнике.
Синхронизация
Синхронизация относится к классу проблем, с которыми вы столкнетесь при параллельном программировании. Когда вы начинаете несколько задач одновременно, в какой-то момент в будущем эти задачи должны "объединиться", возможно, чтобы объединить их результаты. Тип синхронизации управляет этим процессом, чтобы гарантировать, что результат задачи не используется до тех пор, пока он не будет завершен.
Другой тип синхронизации используется для предотвращения вмешательства параллельных задач друг в друга. Если у вас есть код, который не является потокобезопасным, может потребоваться предотвратить одновременный доступ к этому коду двух процессов. Точно так же при работе с изменяемыми данными может потребоваться обеспечить, чтобы две или более задач не могли получить доступ к этим данным одновременно. С этим можно справиться несколькими способами. В идеале проблемы синхронизации должны быть устранены с помощью алгоритмов, которые их предотвращают. На самом деле решения некоторых задач не имеют таких алгоритмов блокировки используются механизмы, которые останавливают доступ к коду или данным до тех пор, пока поток, удерживающий блокировку, не освободит ее. Это может серьезно повлиять на производительность, особенно при использовании большого количества процессоров, которые все должны получить доступ к блокируемому коду.
Состояние гонки
Состояние гонки возникает, когда параллельные задачи зависят от общих данных, как правило, когда синхронизация вокруг этих данных не реализована правильно. Один процесс может выполнять операции с использованием общих данных, которые временно оставляют значение в несогласованном состоянии. Если другой процесс использует несогласованные данные, может произойти непредсказуемое поведение. Хуже того, ошибки могут возникать лишь изредка и их трудно предсказать или воссоздать.
Давайте рассмотрим простой пример. У нас может быть программа, которая увеличивает переменную счетчика в два раза. На однопроцессорной машине это происходило бы последовательно. Процесс и созданное состояние показаны в таблице ниже. В столбце счетчик отображается значение основной переменной счетчика после каждой операции. TempCounter показывает значение временной переменной, используемой в процессе:

Процесс дает ожидаемый конечный результат. Мы начали с нуля, дважды добавили единицу и получили ответ "два". Однако, если эта программа была разложена так, что каждая итерация из трех шагов могла быть выделена другому процессору, мы видим условие гонки. Это объясняется в следующей таблице. В этом случае существует временный счетчик для каждого процессора и одна операция инкремента, происходящая на каждом процессоре. Процессоры показаны как #1 и #2.
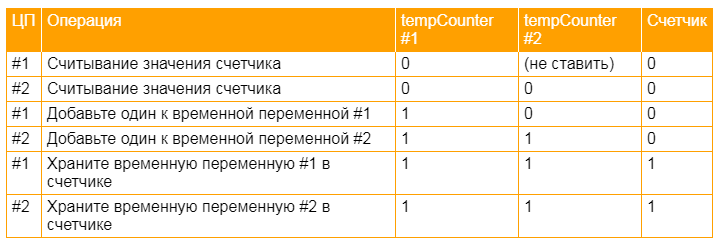
В этом сценарии мы получаем неверный конечный результат, потому что второй задаче было разрешено считывать переменную счетчика, пока она находилась в несогласованном состоянии. Это тонкая и потенциально прерывистая ошибка, которую может быть очень трудно отследить.
Блокировка
Чтобы избежать проблем с синхронизацией, вы можете использовать блокировки. Блокировка может быть запрошена одной задачей, чтобы предотвратить ввод раздела кода или доступ к общей переменной состояния другой задачей. Это метод, который может быть использован для синхронизации потоков и предотвращения условий гонки. Когда процесс запрашивает блокировку, которая уже была предоставлена другому потоку, первый процесс прекращает выполнение и ожидает освобождения блокировки. Говорят, что остановленный поток был заблокирован. Обычно заблокированный поток в конечном итоге получает блокировку и продолжает работать в обычном режиме. Однако при чрезмерной блокировке некоторые процессоры могут простаивать, так как им не хватает работы. Это влияет на производительность.
Взаимная блокировка
Тупиковая блокировка-это крайнее состояние блокировки, включающее два или более процессов. В простейшей ситуации у вас могут быть две задачи, каждая из которых блокируется другой. Поскольку каждая задача блокируется и не будет продолжаться до тех пор, пока другая не освободит свою блокировку, тупик не может быть нарушен, и обе задачи потенциально будут заблокированы навсегда.
Параллельное программирование в .NET 4.0
В ходе этого урока мы рассмотрим классы параллельного программирования, предоставляемые платформой .NET framework. Мы будем смотреть на две библиотеки. Это библиотека параллельных задач (TPL) и параллельная версия интегрированного в язык запроса (PLINQ)
Библиотека параллельных задач
Библиотека параллельных задач обеспечивает параллелизм, основанный как на данных, так и на декомпозиции задач. Параллелизм данных упрощается с появлением новых версий цикла for и цикла foreach, которые автоматически декомпозируют данные и разделяют итерации на все доступные процессорные ядра.
Параллелизм задач обеспечивается новыми классами, которые позволяют определять задачи с помощью лямбда-выражений. Вы можете создавать задачи и позволить платформе .NET framework определять, когда они будут выполняться и какой из доступных процессоров будет выполнять эту работу.
TPL обеспечивает императивную форму параллельного программирования. Независимо от того, решите ли вы использовать декомпозицию данных или декомпозицию задач, ваш код точно определяет, как работает ваш алгоритм.
Параллельный LINQ
Параллельный подход LINQ является скорее декларативным, чем императивным, как и последовательная версия LINQ. Этот подход к параллелизму имеет более высокий уровень, чем тот, который обеспечивается TPL. Он позволяет использовать стандартные операторы запросов, с которыми вы должны быть знакомы, при этом автоматически назначая работу, выполняемую одновременно доступными процессорами.
Преимущества
Новая функциональность параллельного программирования в .NET framework предоставляет ряд преимуществ, которые делают его предпочтительным выбором по сравнению со стандартной многопоточностью. При ручном создании потоков вы можете создать слишком много, что приведет к чрезмерным операциям переключения задач, влияющим на производительность. Вы также можете создать два нескольких, оставив процессоры простаивать. Таковы некоторые из ключевых проблем, на решение которых нацелены новые классы.
И TPL, и PLINQ обеспечивают автоматическую декомпозицию данных. Хотя вы можете контролировать разложение, обычно достаточно стандартного поведения. Такое поведение разумно. Например, после декомпозиции и распределения работы постоянно учитывается активность каждого процессора. Если выясняется, что работа, назначенная одному процессору, занимает больше времени, чем работа другого, используется алгоритм кражи работы для передачи работы от занятого процессора к недостаточно используемому.
Важно понимать, что новые библиотеки обеспечивают потенциальный параллелизм. При стандартной многопоточности, когда вы запускаете новый поток, он сразу же начинает свою работу. Возможно, это не самый эффективный способ использования доступных процессоров. Библиотеки параллелизма могут запускать новые потоки при наличии процессорных ядер. Если это не так, задачи могут быть отложены до тех пор, пока ядро не станет свободным или пока результат операции не будет действительно необходим.
Наконец, новые библиотеки позволяют вам не беспокоиться о количестве доступных ядер и количестве, которое может быть доступно на будущих компьютерах. Все доступные ядра будут использоваться по мере необходимости. Если код выполняется на однопроцессорной машине, он будет выполняться в основном последовательно. Библиотеки параллелизма создают небольшие накладные расходы, поэтому параллельный код, выполняемый на одноядерной машине, будет выполняться медленнее, чем чисто последовательный код. Однако это воздействие незначительно по сравнению с полученными выгодами.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты