Демонстрация Q-learning в программе на Java
Q-Learning - это базовая форма обучения с подкреплением, которая использует Q-значения (также называемые значениями действий) для итеративного улучшения поведения обучаемого агента. В этой заметке я немного расскажу о ней, а также анонсирую новую программу на Java, демонстрирующую алгоритм Q-Learning на примере простой игры.
‘Q’ в q-learning означает качество. Качество в этом случае представляет, насколько полезно данное действие в получении некоторой будущей награды. Когда q-learning выполняется, мы создаем то, что называется q-таблицей или матрицей, которая следует форме [state, action]; инициализируем значения нулем. Затем мы обновляем и сохраняем наши q-значения после каждого эпизода. Эта q-таблица становится справочной таблицей для нашего агента, чтобы выбрать лучшее действие на основе q-значения.
Способы взаимодействия
Агент взаимодействует со средой одним из двух способов. Первый - использовать q-таблицу в качестве ссылки и просматривать все возможные действия для данного состояния. Затем агент выбирает действие на основе максимального значения этих действий. Это называется эксплуатацией, так как мы используем информацию, имеющуюся в нашем распоряжении, чтобы принять решение.
Второй способ действовать - действовать случайным образом. Это называется исследованием. Вместо выбора действий на основе максимального будущего вознаграждения мы выбираем действие случайным образом. Случайное действие важно, поскольку оно позволяет агенту исследовать и открывать новые состояния, которые в противном случае не могут быть выбраны в процессе эксплуатации. Вы можете сбалансировать разведку/эксплуатацию с помощью epsilon (ε) и установить значение того, как часто вы хотите исследовать или эксплуатировать.
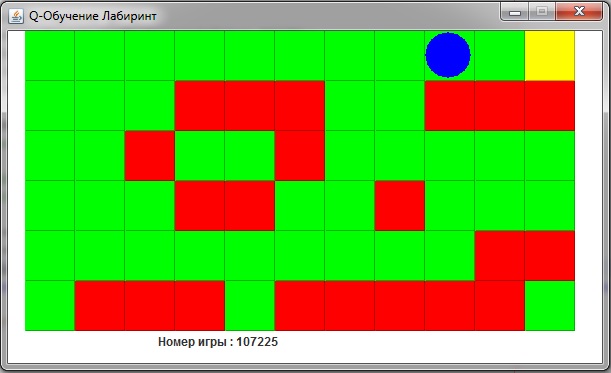
Но основе этой информации мы создадим программу на Java Лабиринт. В этой программе используется базовый алгоритм q-обучения для навигации. Агент не имеет предварительных знаний о стенах (красные блоки) или о конечном местоположении (желтый блок), он учится исключительно через переживание последствий своих действий.
Правила игры
- Есть агент (синий круг), который пытается найти конец лабиринта. Агент всегда начинает в левом нижнем углу доски. Новая доска создается для каждого запуска.
- Есть три блока, по которым агент может перемещаться.
- Красный блок - это ловушка, заставляющая агента начинать все с начала.
- Зеленые блоки являются нейтральными, и агент не получает отклика от входа в это состояние.
- Желтый блок - это объективное состояние, конец игры.
Параметры агента
- gamma: коэффициент дисконтирования для будущих наград
- epsilon: вероятность того, что агент сделает случайный ход
- alpha: скорость обучения для агента
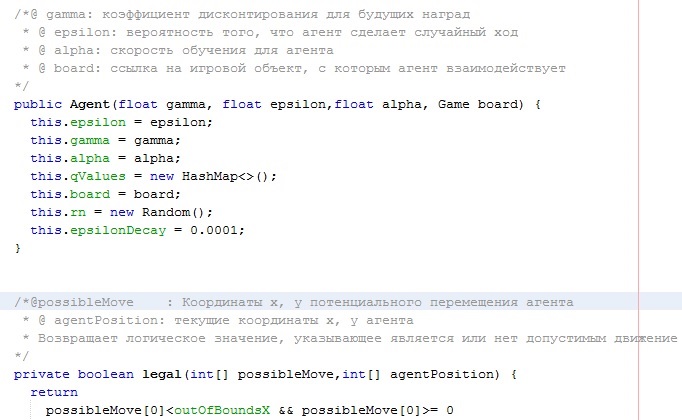 Эти параметры пользователь задает самостоятельно перед компиляцией проекта. Вы сами можете изменять их посмотреть результат обучения – число игр. При некоторых значениях данных параметров обучение может затянуться.
Эти параметры пользователь задает самостоятельно перед компиляцией проекта. Вы сами можете изменять их посмотреть результат обучения – число игр. При некоторых значениях данных параметров обучение может затянуться.
Структура программы Java Q-Learning
В проекте три файла:
- Agent.java
- Game.java
- Q_learning.java

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты