Стек Java
Сегодня будем говорить об алгоритмах и структурах данных для реализации фундаментальных типов данных — мультимножества, очереди и стека. Может быть, вы немного знакомы с ними, но сегодня мы рассмотрим их подробно. Начнем со стека.
Идея в том, что во многих приложениях есть множества объектов для обработки. Это простые операции. Нужно добавлять элементы к коллекции, удалять элементы из неё, проходить по всем объектам, проводя над ними какие-либо операции, проверять, не пуста ли она. Намерения вполне понятные. Ключевой момент: когда нужно удалить элемент коллекции, какой именно удалять? Есть две классические структуры данных: стек и очередь. Они различаются выбором элемента для удаления. В стеке мы удаляем последний добавленный элемент.
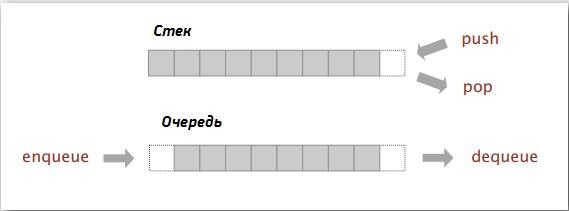
Термины, которые мы используем: push для вставки элемента и pop для удаления последнего добавленного элемента. Подход называется LIFO (last in first out)— последний зашел - первый вышел. Для очереди мы берем добавленный раньше всех элемент. Чтобы не путаться в операциях, добавление элемента назовем NQ, а удаление — DQ. Этот способ называется FIFO (first in first out) — первый пришел - первый вышел. Посмотрим, как всё это реализовать.
Подтемой сегодня будет модульное программирование. Идея в том, что бы полностью разделять интерфейс и реализацию. При наличии четко определенной структуры и типов данных, как стек или очередь, мы полностью скрываем детали реализации от клиента. Клиент может выбрать различные реализации но код должен использовать только базовые операции.
С другой стороны, реализация не может знать детально потребности клиента. Код должен лишь реализовать операции. В этом случае, многие клиенты могут использовать одну реализацию. Мы можем создавать модульные, многократно используемые библиотеки алгоритмов и структур данных, из которых строятся более сложные алгоритмы и структуры данных. Это позволяет при необходимости сосредоточиться на быстродействии. Это модульный стиль программирования, который возможен благодаря объектно-ориентированным языкам, как Java. Будем придерживаться этого стиля. Начнем разговор со стеков.

Давайте тщательно разберем реализацию стека прямо сейчас. Для разминки предположим, что у нас есть коллекция строк. Они могут быть короткими или длинными. Мы хотим иметь возможность сохранять коллекцию строк, удалять и выводить последние добавленные строки, проверять, пуста ли она.
Так вот наше API, конструктор для создания пустого стека. Для вставки используется метод push, аргумент которого — строка, для удаления — метод pop, который выводит строку, добавленную последней. Метод isEmpty возвращает логическое значение. В некоторых приложениях, мы будет включать метод Size.
Как обычно, сначала напишем клиент, а затем разберем реализацию.
public static void main(String[] args)
{
StackOfStrings stack = new StackOfStrings();
while (!StdIn.isEmpty())
{
String s = StdIn.readString();
if (s.equals("-")) StdOut.print(stack.pop());
else stack.push(s);
}
}
Наш клиент читает строки из стандартного ввода и использует команду pop, которую обозначим дефисом. Итак, этот клиент читает строки из стандартного ввода. Если строка равна знаку дефис, берем строку сверху стека и печатаем её. В противном случае, если строка не равна дефису, она добавляется наверх стека.
Рассмотрим пример.
% more tobe.txt to be or not to - be - - that - - - is % java StackOfStrings < tobe.txt to be not that or beЕсть файл tobe.text, клиент будет вставлять строки "to be or not to" в стек. Затем, когда дело доходит до дефиса, он выдаст последний добавленный элемент, в данном случае это "to". Затем добавит "be" наверх стека и выдаст верхний элемент стека, то есть "be" и элемент, добавленный последним. Т.е. "Be" уйдет, "to" тоже, за ними идет "not" и так далее. Этот простой тестовый клиент можно использовать для проверки наших реализаций. Посмотрим код для реализации стека.
Первая реализация использует односвязный список. О связных списках можно подробнее почитать здесь. Нужно хранить односвязный список, который состоит из узлов, в свою очередь состоящих из строки и ссылки на следующий элемент списка.
В реализации стека, когда мы делаем добавление (push), то вставляем новый узел в начало списка. Когда извлекаем элемент, то удаляем первый элемент списка. Это последний добавленный элемент. Посмотрим, как выглядит этот код. Используем внутренний класс Java. То есть будем манипулировать объектами "узел", каждый из которых состоит из строки и ссылки на другой объект "узел". Таким образом операция pop для списка реализуется очень просто. Во-первых нужно вывести первый элемент в списке, поэтому сохраняем его. Возьмем first.item и сохраним в переменную item.
Чтобы избавиться от первого узла, просто сдвигаем указатель первого элемента списка на следующий за ним элемент. Теперь первый элемент готов быть удаленным сборщиком мусора. Остается только вывести элемент, который мы сохранили. Это была операция pop. Что насчет push операции?
Мы хотим добавить новый элемент в начало списка. Первое: сохраняем указатель на начало списка. Это oldfirst = first. Затем создаем новый узел, который поместим в начало списка. Это: first = new Node. Затем присваиваем ему значения. В поле item — строку, которую хотим вставить в начало списка В этом случае "not". И в поле next вставим указатель oldfirst, который теперь второй элемент списка. Так после этой операции, "first" указывает на начало списка. Элементы списка расположены в обратном порядке относительно их добавления в стек.
private class Node
{
String item;
Node next;
}
Эти 4 строки реализуют стековую операцию push(). А вот полная реализация на базе связного списка всего кода для реализации стека строк в Java. В этом классе конструктор ничего не делает, поэтому его нет.
public class LinkedStackOfStrings
{
private Node first = null;
private class Node
{
String item;
Node next;
}
public boolean isEmpty()
{ return first == null; }
public void push(String item)
{
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
}
public String pop()
{
String item = first.item;
first = first.next;
return item;
}
Вот внутренний класс, который мы используем для элементов списка. Делаем его внутренним, чтобы ссылаться напрямую на него. И тогда единственной переменной стека является ссылка на первый узел в списке, и она на старте равна null. Тогда isEmpty просто проверка first на null. Push — это четыре строки кода, которые я уже показывал, pop — это 3 строки кода, которые были даны раньше. Это полный код односвязного списка, который является хорошей реализацией спускающегося списка для любого клиента.
Можно проанализировать алгоритм и предоставить информацию о его быстродействии клиентам. В этом случае видно, что каждая операция в худшем случае тратит постоянное время. Всего несколько инструкций для каждой из операций. Тут нет циклов. Это, очевидно, весьма неплохо.
Что насчет памяти?
Зависит от реализации и компьютера, здесь проанализирована типичная java реализация. Вы можете проверить её для различных сред выполнения, так что она показательна. Для каждого объекта в Java 16 байт идет на заголовок. Дополнительно 8 байт, потому что это внутренний класс. В классе Node есть 2 встроенные ссылки: одна на строку, другая на узел, каждая из них — 8 байт. Итак 40 байт для записи стека.
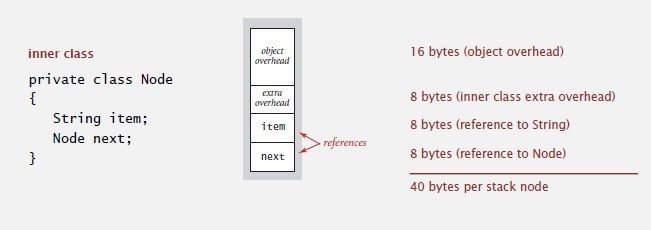
Если у нас есть стек размером N, он займет 40 N байт. Ещё немного занимает first элемент, это около N для целого стека. При большом N значение 40*N точно оценивает требуемую память. Оно не учитывает место для самих строк внутри клиента. Но с этим мы можем правильно оценить затраты ресурсов реализацией для различных клиентских программ.
Время постоянное, но есть и более быстрые реализации стека. Если стек используется во внутренних циклах неких алгоритмов, то важно поискать более быстрые реализации. Другой способ реализации стека — это использование массива для хранения элементов. Посмотрим на него.
Выбор между связанными структурами и массивами является фундаментальным и будет возникать снова и снова при разборе более продвинутых структур данных и алгоритмов. Рассмотрим массив применительно к стеку, чтобы быть готовыми к более продвинутым приложениям в дальнейшем.
При использовании массива, мы просто держим N элементов стека в массиве. И позиция массива c индексом N — это место расположения вершины стека, куда должен быть помещен следующий элемент. Таким образом, для push(), мы просто добавляем новый элемент в s[N]. А для pop() удаляем элемент s[N-1] и уменьшаем N.
Есть большой минус при использовании массива — его размер должен быть объявлен заранее, значит стек имеет ограниченную вместимость. С этим придется считаться, если количество элементов стека превышает размеры массива. Это фундаментальная проблема, с которой приходится иметь дело при любых структурах данных алгоритмов. В данном простом примере это окупится.
Итак, вот полная реализация стека, использующая массив для представления структуры стека. Здесь переменная экземпляра, представляющая собой массив строк. А также наша переменная N, которая представляет собой как размер стека, так и индекс следующей свободной позиции.
public class FixedCapacityStackOfStrings
{
private String[] s;
private int N = 0;
public FixedCapacityStackOfStrings(int capacity)
{ s = new String[capacity]; }
public boolean isEmpty()
{ return N == 0; }
public void push(String item)
{ s[N++] = item; }
public String pop()
{ return s[--N]; }
}
У этого класса есть конструктор. Он создает массив. Здесь мы немного сжульничали для упрощения, займемся этим позже. Обман состоит в требовании указывать размер стека. Это нормально для некоторых приложений, но слишком обременительно для многих других.
Клиент не знает размеров стека. Ему может потребоваться множество стеков одновременно. Они могут достичь максимальной вместимости в разное время. Нужно избавиться от такого требования, и мы это сделаем. Но, код становится почти тривиальным, если мы явно используем вместимость. Для проверки на пустоту мы проверяем, равен ли N нулю.
Для размещения элемента используем N как индекс массива, помещаем туда элемент и увеличиваем N. Вот это, N++, используется во многих языках программирования как сокращение для "используй индекс и увеличь его на 1". А для pop() мы уменьшаем индекс, затем используем его для возврата элемента массива. Таким образом, каждая из операций является однострочной. Это прекрасная реализация для некоторых клиентов. Это реализация стека с помощью массива, но она ломает API, требуя от клиента указания вместимости стека.
Итак, что с этим делать? Есть пара вещей, которые мы не рассмотрели. Мы не написали кода для выброса исключения, если клиент пытается извлечь элемент из пустого стека. Вероятно, следует это сделать. А что случится, если клиент поместит слишком много элементов? Поговорим об изменении размера, которое позволяет избежать переполнения.
Вопрос ещё в том, могут ли клиенты вставлять null элементы в структуру данных. В данном случае мы это позволяем. Но нужно позаботиться о проблеме лойтеринга, когда в массиве хранится ссылка на объект, который на самом деле не используется. Когда мы удаляем значение стека, то в массиве остается ссылка на него. Мы знаем, что больше не используем его, а Java нет.
Для более эффективного использования памяти нужно устанавливать удаленные элементы в Null. Так, чтобы не оставалось ссылок на старые элементы, и сборщик мусора мог освободить память, так как на неё больше никто не ссылается. Это деталь, но для максимально эффективного использования памяти необходимо это учесть.
public String pop()
{
String item = s[--N];
s[N] = null;
return item;
}

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
Читайте также:

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты