Введение в регулярные выражения
Регулярные выражения чрезвычайно удобны и удивительно мощны для поиска и обработки текстовых строк, особенно при работе с текстовых файлами. Одна строка regex может легко заменить несколько дюжин строк кода.
Regex поддерживается во всех языках сценариев (таких как Perl, Python, PHP и JavaScript); а также языках программирования общего назначения, таких как Java; и даже в текстовых процессорах, таких как Word для поиска текстов. Начало работы с regex может быть нелегким из-за его синтаксиса, но это, безусловно, стоит потраченного времени.
Даже если вы не программист, то понятие регулярных выражений поможет вам, например, при составлении правил перенаправления в файле htaccess на вашем сайте.
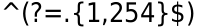
Синтаксис регулярных выражений
Регулярное выражение (или Regex) - это паттерн (или фильтр), который описывает набор строк, который соответствует шаблону. Иными словами, регулярное выражение принимает определенный набор строк и отвергает остальные.
Регулярное выражение состоит из последовательности символов, метасимволы (таких, как ., \d, \D, \С \S, \w, \W) и операторов (таких, как +, *, ?, |, ^). Они строятся путем объединения множества меньших вложенных выражений.
Сопоставление одного символа
Фундаментальные строительные блоки выражений – это соответствующие одному символу. Большинство знаков, включая все буквы (a-z и A-Z) и цифры (0-9), само сопоставление. Например, регулярное выражение x соответствует подстроке "x"; z соответствует "z", и 9 соответствует "9".
Не буквенно-цифровые символы без специального значения в regex также соответствует себе. Например, = соответствует "="; @ соответствует "@".
Специальные символы Regex и Escape-последовательности
Специальные символы Regex
Эти символы имеют особое значение в regex (я подробно расскажу в более поздних материалах):
- метасимвол: точка (.)
- квадратные скобки: [ ]
- анкеры позиции: ^, $
- индикаторы появления: +, *, ?, { }
- скобки: ( )
- или: |
- escape и метасимвол: обратная косая черта (\)
- escape-последовательность
Регулярное выражение также признает общие escape-последовательности, например, \n для перехода на новую строку, \t на вкладке, \r Для возврата каретки, \nnn на срок до 3-значное восьмеричное число, \xhh на два-значный шестнадцатеричный код, \uhhhh для 4-значного юникод, \uhhhhhhhh для 8-значное юникод.
Соответствие последовательности символов (строка или текст)
Под-Выражения
Регулярное выражение строится путем объединения многих мелких суб-выражений или атомов. Например, регулярное выражение Friday совпадает со строкой "Friday". Сопоставление по умолчанию чувствительно к регистру, но может быть установлено в без учета регистра через модификатор.
Или (|) оператор
Вы можете предоставить альтернативы с помощью оператора "или", обозначается вертикальной чертой '|'. Например, регулярное выражение four|for|floor|4 принимает строки "four", "for", "floor" или "4".
Квадратные скобки [...], [^...], [.-.]
Скобочное выражение является списком символов, огороженым [ ]. Он соответствует любому символу в списке. Однако, если первый символ в списке-каре (^), то он соответствует любой символ, не входящий в список. Например, регулярное выражение [02468] соответствует одной цифре 0, 2, 4, 6, или 8; регулярное выражение [^02468] соответствует любому одиночному символу, кроме 0, 2, 4, 6, или 8.
Вместо перечисления всех символов, вы могли бы использовать диапазон выражения внутри скобок. Диапазон выражения состоит из двух символов, разделенных дефисом (-). Он соответствует любому одному символу, который сортируется между двумя символами, включительно. Например, [a-d] такой же, как [abcd]. Вы можете включить курсор (^) в передней части диапазона, чтобы инвертировать соответствующие. Например, [^a-d] эквивалентны [^abcd].
Большинство специальных символов регулярных выражений теряют смысл внутри квадратных скобок, и могут быть использованы как они есть; за исключением ^, -, ] или \.
метасимволы \w, \W, \d, \D, \s, \S
Метасимвол - это символ, имеющий специальное значение в регулярных выражениях.
Метасимвол точка (.) соответствует любому одиночному символу, кроме символа новой строки \n (аналогично [^\n]). Например, ... соответствует любому из 3 символов (включая буквы, цифры, пробелы, но, кроме перевода строки); the.. будет входить в "there", "these", "the " и так далее.
\w (слово символ) соответствует любой одиночной букве, цифре или знаку подчеркивания (аналогично [a-zA-Z0-9_]). Прописная коллегв\а \W (не-слово-символ) соответствует любому одиночному символу, который не совпадает с \w (аналогично [^a-zA-Z0-9_]). В регулярных выражениях, прописной метасимвол - это всегда обратная своей строчной “коллеге”.
\d (цифра) соответствует любая цифра (аналогично [0-9]). Прописная коллега \D (нецифровые) соответствует любому одиночному символу, который не является цифрой (то же самое, что и [^0-9]).
\s (пробел) соответствует любому одиночный символ пробела (так же, как [ \t\n\r\f], пробел, табуляция, перевод строки, возврат каретки и форма подачи). Прописная коллега \S (не пробел) соответствует любому одиночному символу, который не совпадает с \s (аналогично [^ \t\n\r\f]).
Примеры:
- \s\s # соответствует двум пробелам
- \S\S\s # два не-пробела с последующим пробелом
- \s+ # один или более пробелов
- \S+\s\S+ # Два слова (без пробелов), разделенные пробелом
Регулярное использование обратной косой черты (\) необходимо в двух случаях: для метасимволов, таких как \d (цифровая), \D (нецифровые), \s (пробел), \S (не пробел), \w (слово), \W (не-слово). И чтобы избежать специальных регулярных выражений, например, \. для ., \+ для +, \* для *, \? для ?.
Также нужно писать \\ для \ в regex чтобы избежать двусмысленности. Регулярное выражение также признает \n для перехода на новую строку, \t вкладки и т. д.
Обратите внимание, что во многих языках программирования (C, Java, и на Python), обратная косая черта (\) также используется для escape-последовательности в строке, например, "\n" для перехода на новую строку, "\t" на вкладке, и вы также должны написать "\\" для \. Следовательно, чтобы написать регулярное выражение шаблон \\ (который совпадает с одним \) на этих языках, нужно писать "\\\\" (два уровня побег!!!). Аналогичным образом, вам нужно написать "\\d" регулярные выражения метасимвол \d. Это громоздкий путь и нередки ошибки, так что будьте внимательны!
Индикаторы вхождения: +, *, ?, {m}, {m,n}, {m,}
За выражением регулярного выражения может следовать индикатор вхождения (он же оператор повторения):
- ?: Предыдущий элемент является необязательным и сопоставляется не более одного раза (т. е. встречается 0 или 1 раз или необязательно).
- *: Предыдущий элемент будет соответствовать нулю или больше раз, т. е., 0+
- +: Предыдущий элемент будет сопоставлен один или несколько раз, т. е., 1+
- {m}: Предыдущий элемент соответствует точно m раз.
- {m,}: Предыдущий элемент соответствует m или более раз, т. е., m+
- {m,n}: Предыдущий элемент соответствует по крайней мере m раз, но не более n раз.
Модификаторы
Можно применить модификаторы к регулярному выражению, чтобы адаптировать его поведение, например глобальное, без учета регистра, многострочное и т. д. Способы применения модификаторов различаются между языками.
В Java вы применяете модификаторы при компиляции регулярного выражения Pattern. Например,
Pattern p1 = Pattern.compile(regex, Pattern.CASE_INSENSITIVE); // для поиска совпадений без учета регистра Pattern p2 = Pattern.compile(regex, Pattern.MULTILINE); // для многострочной строки Pattern p3 = Pattern.compile(regex, Pattern.DOTALL); // точка (.) соответствует всем символам, включая новую строкуПозиционные якоря ^, $, \b, \B, \<, \<, \A, \Z
Позиционные якоря не совпадают с фактическими символами, но соответствуют позиции в строке, такие как начало строки, конец строки, начало слова, а конец слова.
^ соответствует началу строки. $ соответствует концу. Эти наиболее часто используемые анкеры положения.
\b и \B: \b соответствует границе слова (т. е. начало слова или конец слова); и \B соответствует обратное \b, или не-слово-граница.
Скобки
Скобки ( ) служат двум целям в регулярных выражениях:
Во-первых, скобки ( ) могут использоваться для группирования подвыражений для переопределения приоритета или применение оператора повторения. Например, (abc)+ (можно abc, abcabc, abcabcabc, ...) отличается от abc+ (можно abc, abcc, abccc, ...).
Во-вторых, скобки используются, чтобы обеспечить так называемые обратные ссылки. Обратная ссылка содержит подстроку. Для примера, регулярное выражение (\S+) создается один справочник (\S+), в котором содержится первое слово (последовательный не-пространства) входной строки; регулярное выражение (\S+)\s+(\S+) создает две ссылки: (\S+) и еще один (\S+), содержащая первые два слова, разделенных одним или несколькими пробелами \s+.
Обратные ссылки хранятся в специальных переменных $1, $2, ... (или \1, \2, ... в Python), где $1 содержится подстрока, которая соответствует первой паре скобок, и так далее. Например, (\S+)\s+(\S+) создает две обратные ссылки, которые совпали с первыми двумя словами. Совпавшие слова сохраняются в $1 и $2 (или \1 и \2), соответственно.
Обратные ссылки важны для управления строкой. Например, следующее выражение Perl меняет местами первое и второе слова, разделенные пробелом:
s/(\S+) (\S+)/$2 $1/;Эти функции могут не поддерживаться в некоторых языках.
Положительный просмотр вперед (?=шаблон)
(?=pattern) известен как положительный просмотр вперед. Он выполняет поиск, но возвращает только результат: есть совпадение или нет. Его также называют утверждением, так как он не использует символы в соответствие. Например, следующий сложный regex используется для сопоставления адресов электронной почты AngularJS:
^(?=.{1,254}$)(?=.{1,64}@)[-!#$%&'*+/0-9=?A-z^ _ ' a-z { / }~]+(\.[-!#$%&'*+/0-9=?A-z^ _ ' a-z{|}~]+)*@[A-Za-z0-9] ([a-Za-z0-9-]{0,61}[a-Za-z0-9])?(\.[A-Za-z0-9] ([a-Za-z0-9-]{0,61} [a-Za-z0-9])?)*$
Первый положительный просмотр вперед моделей ^(?=.{1,254}$) задает максимальную длину до 254 символов. Второй положительный просмотр вперед ^(?=.{1,64}@) устанавливает максимум 64 символа перед '@' знаком для имени пользователя.
Отрицательный просмотр вперед (?!шаблон)
Обратное (?=pattern). Если совпадение pattern отсутствует. Например, a(?=b) матчи 'a' в 'abc' (не много 'b'), но не 'acc'. В то время как a(?!b) матчи 'a' В 'acc', но не abc.
Незахватывающие группы (?:шаблон)
Помните, что для записи совпадений можно использовать круглые скобки. Чтобы отключить сбор, использование ?: внутри скобок в виде (?:pattern). Другими словами, ?: отключает создание группы захвата, чтобы не создавать ненужного захвата группы.
Еще не конец
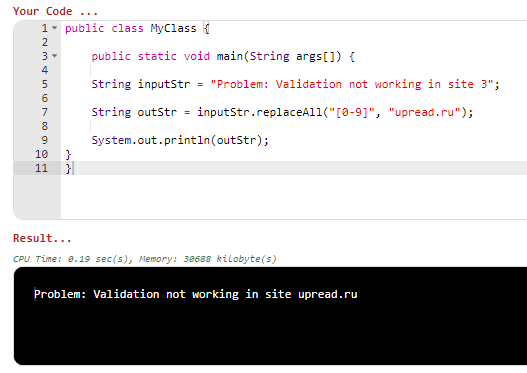
Очень много информации для новичков? На самом деле это даже еще не все. Ничего страшного, за один раз никто никогда и не может все понять и запомнить. Если вам требуется помощь, то вы всегда можете написать мне – за небольшую плату я вам помогу. Возвращайтесь к данной статье как к справочнику, а в следующих статьях я набросаю примеры по языкам программирования Вот один из них. Данная программа на Java с помощью регулярных выражений меняет все вхождения цифр на upread.ru в строке:
public class MyClass {
public static void main(String args[]) {
String inputStr = "Problem: Validation not working in site 3";
String outStr = inputStr.replaceAll("[0-9]", "upread.ru");
System.out.println(outStr);
}
}
Результат:

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты