Реализация недвоичных деревьев
Принципиальное отличие недвоичных деревьев от двоичных состоит в том, что число потомков у вершин может изменяться в достаточно широких пределах. Это не позволяет объявить в каждой вершине какое-то разумное количество ссылочных полей (у двоичных деревьев все просто – по два поля в каждой вершине).
Недвоичные деревья используются реже двоичных, но, тем не менее, есть круг задач, где они необходимы. Пожалуй, наиболее известным примером недвоичного дерева является хорошо всем знакомая структура каталогов в файловых подсистемах операционных систем.
Существуют разные способы описания недвоичных деревьев, среди которых наиболее известны следующие два: сведение недвоичного дерева к двоичному (двоичная модель недвоичного дерева) и описание недвоичного дерева с помощью комбинированной структуры типа «Список списков» (списковая модель недвоичного дерева). Рассмотрим кратко суть каждого их этих способов.
Сведение недвоичного дерева к двоичному выполняется с помощью принципа, который имеет происхождение из генеалогических деревьев и формулируется кратко как «Старший потомок и его братья». Смысл этого принципа состоит в том, что множество связей некоторой родительской вершины с ее потомками заменяется одной связью с самым старшим потомком (им принято считать самого левого потомка), для которого формируется список его братьев (все они дети одного родителя). Так происходит для каждой родительской вершины, и в итоге получается двоичное дерево весьма специфического вида (но главное, что оно двоичное!).
Все сказанное проиллюстрируем конкретным примером. На следующем рисунке приводится исходное недвоичное дерево, в котором жирными стрелками уже выделены связи родителей со своими старшими потомками:
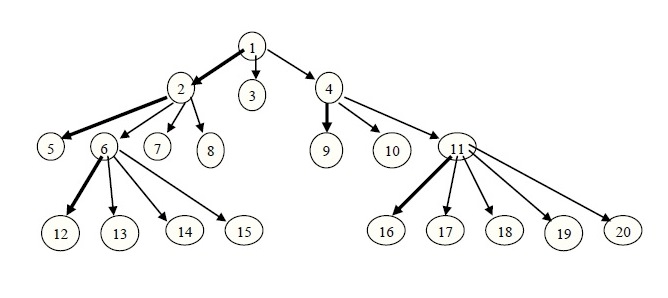
На следующем рисунке связи родителей со своими потомками заменены новыми связями старших потомков со своими братьями (для наглядности эти связи показаны пунктиром):
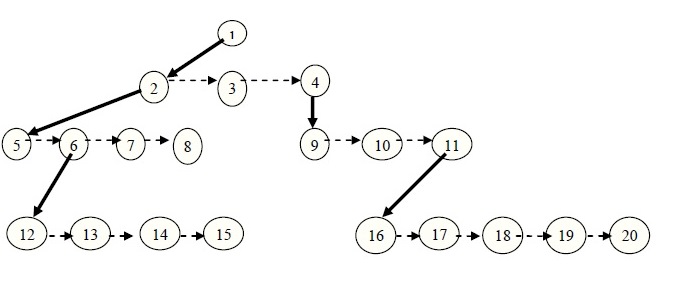
На данном рисунке не совсем понятно, что полученное дерево действительно является двоичным, хотя у него нет ни одной вершины с более чем двумя потомками (да и с двумя потомками вершин очень мало – только вершины 2 и 6). Для наглядности далее приводится еще один рисунок, где вершины двоичного дерева представлены в более привычном виде, с левыми и правыми потомками. Кроме того, опять же для наглядности маленькими стрелками показаны отсутствующие (пустые) связи.
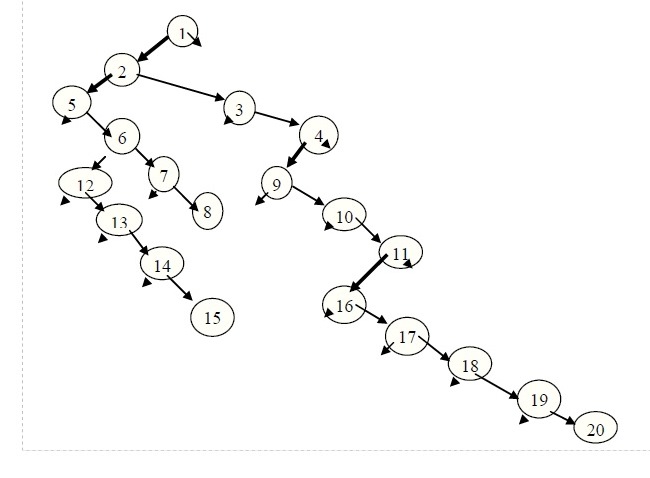
Конечно, полученное двоичное дерево весьма необычно, и специфика его проявляется еще и в том, что адресные поля вершин имеют четкую специализацию и принципиально различаются по смыслу: левое поле используется для адресации старшего потомка, правое – для адресации очередного брата в списке братьев-потомков одной и той же вершины.
Полученное двоичное дерево можно реализовать стандартным образом как набор вершин-записей, размещаемых в динамически распределяемой памяти. Это позволяет использовать для обработки недвоичного дерева известные алгоритмы работы с двоичными деревьями. Правда, эти алгоритмы приходится дорабатывать, чтобы учесть специфику недвоичных деревьев.
Рассмотрим кратко возможные реализации основных операций с недвоичными деревьями на базе алгоритмов обработки двоичных деревьев.
Прежде всего, надо сделать объявления, необходимые для реализации двоичной модели недвоичного дерева:
- описать структуру вершин двоичного дерева с информационным полем и двумя специализированными адресными полями;
- ввести основную переменную – указатель на корневую вершину двоичного дерева.
Добавление новой вершины как потомка заданной вершины включает в себя:
- поиск заданной вершины;
- если заданная вершина найдена, выделяется память для новой вершины и заполняются ее поля, в том числе и оба адресных нулевых поля;
- если заданная вершина пока еще не имеет потомков (признак - нулевое левое адресное поле), то новая вершина становится этим единственным потомком, для чего ее адрес заносится в левое адресное поле заданной вершины;
- если заданная вершина уже имеет потомков, то через ее левое адресное поле определяется старший потомок, который является первым элементом в списке братьев, и выполняется добавление новой вершины в этот список;
- простейший вариант добавления – в начало списка сразу за старшим потомком;
- для добавления в конец списка необходимо пройти по правым адресным полям всех братьев.
- поиск удаляемой вершины с определением ее родителя;
- если удаляемая вершина не имеет потомков (признак - пустое левое адресное поле), то возможны два случая:
- удаляемая вершина не является старшим потомком и поэтому просто удаляется из списка братьев стандартным образом (используются правые адресные поля вершин) (вершины 3, 7, 8, 10, 13-15, 17-20);
- удаляемая вершина – старший потомок (например 5, 9, 12, 16); здесь надо изменить адрес старшего потомка у родителя, записав в его левое адресное поле адрес следующего по порядку брата (вместо вершины 5 старшей становится вершина 6, вместо 9 – 10 и т.д.);
-
более сложная ситуация возникает в случае удаления вершины с потомками; возникает вопрос: что делать с этими потомками? Возможные варианты:
- запретить удаление таких вершин (обычно это соглашение применяется к корневой вершине дерева);
- удалить вместе с вершиной и всех его потомков, что можно сделать за счет рекурсивного обратного обхода вершин поддерева с корнем - удаляемой вершиной; после этого удаляемая вершина обрабатывается как не имеющая потомков (такое удаление можно назвать «жестким»);
- передать всех потомков родителю удаляемой вершины («мягкое» удаление); в этом случае в списке братьев удаляемой вершины вместо нее появляется список ее непосредственных потомков. Здесь приходится рассматривать два подслучая – более простой, когда удаляемая вершина не является старшим потомком, и чуть более сложный – когда является (придется заменить левое адресное поле у родителя).
Теперь рассмотрим второй способ представления недвоичных деревьев – списковый. Суть его в том, что для описания исходного недвоичного дерева используется комбинированная структура типа «Список списков»: создается основной список, в который включаются все и только родительские вершины (список родителей); с каждым элементом основного списка связывается дополнительный список, содержащий всех непосредственных потомков данного родителя (список детей).
Пример. Исходное недвоичное дерево (выделены родительские вершины):
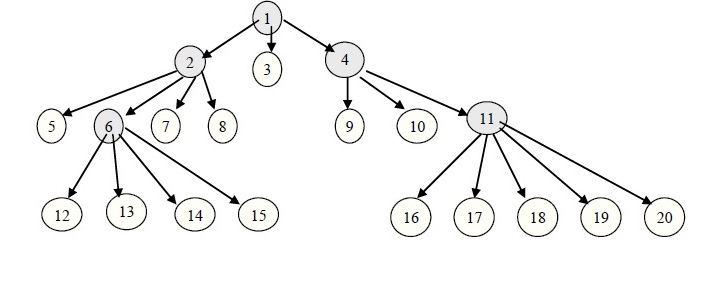
Списковое представление дерева:
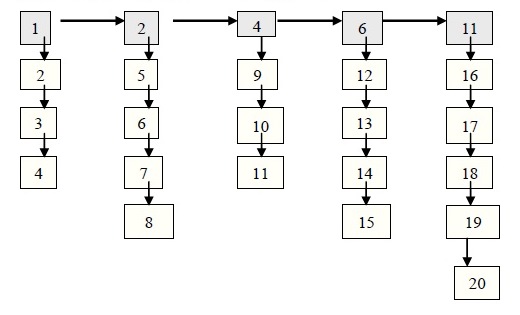
Основной и дополнительные списки реализуются как динамические, т.к. в общем случае заранее неизвестно ни количество родительских вершин, ни количество потомков у них. Для описания комбинированной структуры как обычно необходимо:
- описать структуру элементов списков детей с обязательным адресным полем для указания следующего элемента списка;
- описать структуру элементов основного списка родителей с двумя обязательными адресными полями – указатель на следующий элемент основного списка и указатель на первый элемент списка потомков;
- ввести основную переменную – указатель размещения в памяти первого элемента основного списка родителей.
- поиск заданной вершины; если заданная вершина найдена в списке родителей, то новая вершина просто добавляется в список ее потомков;
- если заданная вершина найдена лишь в каком-то списке потомков, но отсутствует в списке родителей, то:
- добавляем заданную вершину в список родителей;
- создаем для этой вершины одноэлементный список потомков с новой вершиной.
- поиск вершины;
- если вершина найдена только в каком-то списке потомков (она не является родительской), то:
- она удаляется из этого списка;
- список проверяется на пустоту, и если он стал пустым, то соответствующая родительская вершина удаляется из списка родителей, поскольку потомков у нее теперь нет;
- если удаляемая вершина найдена в родительском списке, то реализуется одна из возможных стратегий:
- отменить удаление как невозможное в связи с наличием у удаляемой вершины потомков (например, для корня дерева);
- выполнить «жесткое» удаление: найти и удалить всех потомков и лишь после этого удалить саму заданную вершину;
- выполнить «мягкое» удаление: найти родителя удаляемой вершины и в его список потомков добавить список потомков удаляемой вершины.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.


 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты