Что плохого в классах-обертках чисел на Java?
А на самом деле, что плохого в классах-обертках чисел на Java? Ознакомьтесь с этой статьей, чтобы узнать больше о том, как они могут тратить память и загружать сборщик мусора для ваших приложений.
В Java обертки являются экземплярами классов, таких как java.lang.Integer или java.lang.Double , которые обертывают или "упаковывают" соответствующие примитивные типы:int, double, и т.д. Они были разработаны, чтобы позволить приложениям Java передавать числа как объекты и, что более важно, хранить числа в общих коллекциях, таких как java.util.ArrayList, java.util.HashMap, и т.д. Необходимость хранить номера в списках и картах очень распространена. Чтобы удовлетворить её, разработчики JDK имели два варианта:
- Обеспечьте специализированные коллекции, т. е. списки и карты, для каждого примитивного типа и их комбинаций. Например, это может включать IntArrayList, ObjectToDoubleHashMap, IntToObjectLinkedHashMap, IntToLongConcurrentHashMap, и т.д.
- Дайте способ повторного использования существующих коллекций для чисел.
Чтобы проиллюстрировать этот момент, давайте проведем небольшой эксперимент. Простая программа ниже создает большой массив long чисел и переходит в спящий режим:
public class BoxedNumMemory {
private static final int NUM_NUMS = 10 * 1000 * 1000;
private static long[] nums = new long[NUM_NUMS];
public static void main(String args[]) throws InterruptedException{
for (int i = 0; i < NUM_NUMS; i++) {
nums[i] = (long) i;
}
System.out.println("Инициализация массива; идем спать...");
Thread.sleep(1000000000); }}
Скомпилируйте эту программу и запустите ее. Затем в отдельном окне консоли вызовите jps утилиту JDK, чтобы определить PID JVM, выполняющего это приложение, а затем вызовите:
jmap -histo:live <BoxedNumMemory JVM pid>Приведенная выше команда присоединится к нашей JVM, отсканирует ее кучу и напечатает гистограмму всех живых объектов — то есть, сколько памяти занимает все экземпляры каждого класса. Если вы используете Oracle JDK и HotSpot JVM, как и большинство из нас в настоящее время, ваш вывод будет выглядеть следующим образом:
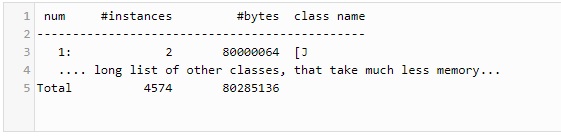
Как вы можете видеть, большая часть памяти берется нашим единственным long[] массивом (J - это историческое внутреннее имя JVM для long типа; второй небольшой массив происходит от внутренних JVM). Каждый элемент массива занимает восемь байт, как и ожидалось.
Теперь замените два символа в одной строке этой программы так, чтобы вместо примитивного массива он создавал массив коробочных чисел:
private static Long[] nums = new Long[NUM_NUMS];Перекомпилируйте программу, повторно запустите ее (обратите внимание, что теперь требуется больше времени для инициализации массива) и снова получите гистограмму объекта. Вы увидите что-то вроде этого:
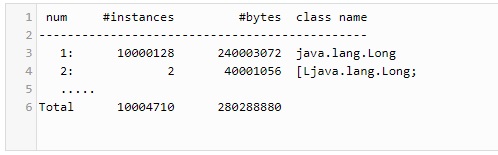
Оказывается, сейчас наша программа использует в 3,5 раза больше памяти! Теперь существует 10 миллионов java.lang.Long объектов (128 дополнительных объектов снова поступают из внутренних систем JVM), и они занимают большую часть кучи. Чтобы быть справедливым, наш большой массив теперь занимает половину памяти, потому что он стал массивом ссылок на объекты, и каждая ссылка занимает четыре байта (или восемь байтов, если ваш максимальный размер кучи выше 32 ГБ ). Однако экономия невелика по сравнению с убытками.
Простое деление приведенных выше чисел предполагает, что размер одного java.lang.Longобъекта составляет 24 байта. Если он обертывает одно восьмибайтовое длинное число, то почему оно такое большое?
Общий ответ на это - из-за "фиксированных накладных расходов на объектную память в JVM". HotSpot JVM (и большинство других JVM) должны искать компромиссы для поддержки виртуального вызова метода, сборки мусора и блокировки объекта (под последним мы подразумеваем, что спецификация языка позволяет использовать каждый объект в качестве аргумента synchronized объявление.) Каждый из этих механизмов требует, чтобы некоторая дополнительная информация хранилась в памяти на каждый объект Java. А именно, указатель от объекта к его классу необходим для виртуальных методов и GC (сборщик мусора), и некоторые дополнительные биты учета на объект необходимы для GC и блокировки. Для хранения всей этой информации виртуальная машина HotSpot использует так называемый заголовок объекта. Он занимает 12 байт на объект, когда максимальный размер кучи меньше 32 ГБ, и 16 байт в противном случае.
12 байт для заголовка объекта плюс восемь байт для примитивного длинного числа дают нам 20 байт - так почему же java.lang.Long экземпляры фактически используют 24 байта? Это следствие еще одного компромисса. Это было сделано разработчиками HotSpot VM, чтобы позволить приложениям Java работать с кучей больше, чем 4 ГБ, используя короткие, экономичные четырехбайтовые указатели для ссылок на объекты.
Вот как это работает. Четыре байта составляют 32 бита; 32 бита позволяют нам кодировать числа в 0 ... (4*1024*1024*1024 - 1) диапазон. Это означает, что обычно с помощью четырехбайтового указателя мы можем адресовать только ~4 миллиарда байт или 4 ГБ. Однако разработчики HotSpot придумали хитрый трюк: JVM по умолчанию умножает каждое значение указателя на 8. Так, для указателей со значениями 0, 1 и т.д., реальные адреса памяти становятся 0, 8, 16, ... Это называется восьмибайтовым выравниванием объектов, и это означает, что с короткими ("узкими") четырехбайтовыми указателями JVM теперь может работать с большой кучей 32 ГБ вместо 4 ГБ! В целом, это очень хорошее решение, но оно имеет один нюанс: эффективный размер каждого объекта Java становится пропорциональным восьми байтам. Для каждого объекта с реальным размером 20 или 28 байт, дополнительные четыре байта памяти просто теряются. Для больших объектов относительное количество отходов невелико, но для коробочных чисел это заметно.
Суть заключается в том, что объединенные накладные расходы на заголовок объекта, выравнивание объекта и тот факт, что каждый живой объект коробочного числа нуждается в указателе на него, означает, что, в зависимости от типа, объект коробочного числа требует в 3-5 раз больше памяти, чем соответствующий примитивный тип. Это, кстати, справедливо и для других мелких объектов. Это действительно плохая новость, если ваше приложение сильно зависит от коробочных номеров.
К счастью, для многих приложений это не так. Если ваше приложение использует только несколько карт хэша с несколькими сотнями ключей или значений, которые являются классами обертками, в большинстве случаев, то вы не должны беспокоиться. Однако трудно оценить фактический размер и потребление памяти каждой структуры данных в каждом сценарии. Итак, если вы знаете, что ваше приложение использует коробочные номера, но вы не уверены, сколько памяти это стоит вам, как вы можете это узнать?
Ответ таков: используйте инструмент анализа памяти. Самый простой способ проверить, сколько памяти в вашем приложении потребляется - использовать jmap -histoих, как показано выше. Однако гистограмма объекта не скажет вам, откуда "берутся" обертки, т. е. какие структуры данных хранят и управляют ими, и сколько памяти тратится каждой отдельной структурой. Лучший способ получить эту информацию - взять дамп кучи и проанализировать его.
Дамп кучи - это по существу полный снимок кучи запущенной JVM. Он может быть либо взят в произвольный момент путем вызова jmap утилиты, либо JVM может быть настроен для его автоматического производства, если он не работаетOutOfMemoryError. Если вы загуглите "JVM heap dump", то сразу увидите кучу актуальных статей на эту тему.
Дамп кучи - это двоичный файл размером примерно с кучу вашего JVM, поэтому его можно читать и анализировать только с помощью специальных инструментов. Существует целый ряд таких инструментов, доступных как с открытым исходным кодом, так и коммерческих. Самым популярным инструментом с открытым исходным кодом является Eclipse MAT; есть также VisualVM и некоторые менее мощные, менее известные инструменты. Коммерческие инструменты включают в себя профилировщики Java общего назначения: JProfiler и YourKit, а также один инструмент, построенный специально для анализа дампа кучи под названием JXRay.
В отличие от большинства других инструментов, JXRay сразу же анализирует дамп кучи для большого количества общих проблем, таких как повторяющиеся строки и другие объекты, неоптимальные структуры данных и, да, коробочные числа. Инструмент создаёт отчет со всей собранной информацией в формате HTML. Преимуществом такого подхода является то, что вы можете просматривать результаты анализа в любом месте в любое время и легко делиться ими с другими участниками. Это также означает, что вы можете запустить инструмент на любом станке, включая большие и мощные, но "обезглавленные" машины в центре обработки данных.
JXRay вычисляет накладные расходы (сколько памяти вы сэкономите, если избавитесь от конкретной проблемы) в байтах и в процентах от используемой кучи. Для оберток накладные расходы вычисляются как объем памяти, который будет сохранен, если вы замените каждое коробочное число простым примитивным числом. JXRay группирует вместе все объекты, которые имеют одну и ту же проблему и доступны через одну и ту же цепочку ссылок, например коллекции или массивы, содержащие коробочные номера, а затем объекты, ссылающиеся на них вплоть до корня GC.
Знание того, какие структуры данных ответственны за наибольшие потери памяти, позволяет быстро и точно определить код, который вызывает проблему, а затем внести необходимые изменения.
Если упаковки хранятся в стандартных коллекциях Java, таких как java.util.ArrayList или java.util.HashMap, каков наилучший способ избавиться от связанных отходов памяти? Оказывается, что некоторые сторонние библиотеки доступны, которые предоставляют широкий спектр специализированных коллекций для непосредственного хранения чисел. Любимая библиотека автора - fastutil; другие-GNU Trove и Koloboke. Иногда достаточно просто заменить коллекцию, такую как HashMap<String, Integer> на Object2IntOpenHashMap<String>, и перекомпилировать исходный код. В других ситуациях, например, когда один Object[] массив содержит смесь упакованных числовых объектов различных типов, возможно, вам потребуется выполнить более серьезный редизайн вашего приложения.
Таким образом, упаковки хороши, если они используются в нескольких незначительных частях приложения, но они могут тратить память и создавать давление GC, если большие и важные структуры данных полагаются на них. Лучший способ измерить влияние оберток числовых классов на память вашего приложения - это получить дамп кучи и использовать для его анализа такой инструмент, как JXRay. Если вы обнаружите, что коробочные номера являются проблемой, часто легко избавиться от них, переключившись со стандартных коллекций JDK на специализированные сторонние библиотеки. Но иногда вам может потребоваться внести более глубокие изменения в свой код.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты