Введение в сжатие данных
Сжатие данных почти так же старо, как и компьютеры. Это одно из тех нововведений, которое действительно изменило то, как мы взаимодействуем с медиа. Без этого мы не смогли бы смотреть видео онлайн, быстро отправлять фотографии нашим друзьям или даже создавать резервные копии музыки на наших смартфонах. Если вы когда-нибудь задавались вопросом, как все это работает под капотом, эта статья для вас.
Как работает сжатие данных
Для непосвященных сжатие выглядит как какое-то волшебство. Вы просто нажимаете несколько кнопок, и вуаля – у вас есть файл .zip или .rar, который значительно меньше, чем файлы, с которых вы начали. Как компьютер “знает”, как упаковать все эти данные, ничего не повредив?
Вот тут-то и вступают в игру алгоритмы. Каждый метод сжатия данных имеет определенный набор правил. Например, когда инициируется сжатие текста, компьютер возьмет все пробелы в тексте и назначит им один байт. После этого он упакует байт в строку, которая укажет декодеру, куда все положить обратно.
Сжатие изображений работает аналогично. В зависимости от алгоритма вы можете получить файл меньшего размера с заметно худшим качеством изображения или что-то почти такого же размера и выглядящее практически идентично оригиналу.
Сжатие работает либо путем удаления ненужных данных, либо путем сбора одинаковых или похожих байтов и придания им нового значения, что позволяет компьютеру восстановить исходные данные.
Типы сжатия данных
Два основных типа сжатия называются с потерями и без потерь, так как один меньше, но ухудшает качество изображения или звука, в то время как другой сохраняет качество файла неизменным.
Сжатие с потерями позволяет создавать файлы меньшего размера за счет анализа исходных данных и удаления ненужных битов. Это могут быть соседние пиксели аналогичного цвета или неиспользуемые частоты в песне. При правильном выполнении сжатие с потерями дает хорошие результаты, которые очень близки к исходной работе.
Однако более агрессивный алгоритм сжатия приводит к значительной потере данных в конечном продукте – фотография может выглядеть неровной, вы услышите, что в песнях отсутствуют определенные звуки, а видео превратится в беспорядочный беспорядок.
Сжатие данных без потерь дает гораздо лучшие результаты, если вы готовы пожертвовать местом для хранения. Это также неразрушающий процесс. Вместо прямого удаления байтов с одинаковым значением алгоритм подсчитывает их и заменяет блок байтом, обозначающим количество замененных блоков. Идея состоит в том, чтобы сохранить структуру исходного файла (файлов).
Именно так работает большинство инструментов и форматов архивирования, поэтому при распаковке архивов, созданных таким образом, вы получаете исходные файлы. Сжатие без потерь используется в ситуациях, когда сжатие с потерями может привести к непоправимому повреждению файлов, таких как исполняемые файлы. Он также популярен среди меломанов, стремящихся сохранить качество своих музыкальных записей.
Как работают алгоритмы сжатия?
Разные алгоритмы работают по-разному, но многие из них основаны на деревьях Хаффмана.
Каждый байт состоит из 8 бит с 256 различными возможными комбинациями, такими как 00000000, 00000001, 00000010, 00000011 и так далее и тому подобное. Однако эти комбинации появляются только с равной вероятностью в случайных данных. В неслучайных данных, скорее всего, некоторые появляются чаще, чем другие.
Вот таблица частот букв в английском языке.
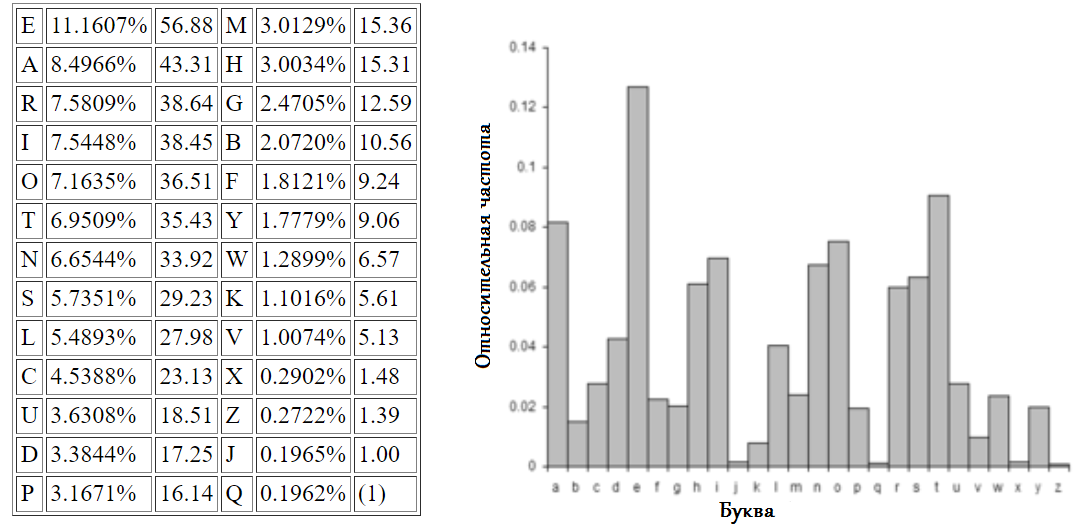
Поскольку мы храним 1 байт для представления каждой буквы, байт, представляющий букву E, будет появляться гораздо чаще, чем байт, представляющий, скажем, букву X.
Байт, представляющий E, равен 01000101, а X - 01011000. Обратите внимание, что длина в битах одинакова, они оба занимают по 8 бит данных каждый, но мы редко используем X, в то время как мы часто используем E.
Что мы представляем E с более коротким двоичным значением? Мы могли бы, но тогда, чтобы две буквы не имели одного и того же двоичного значения, нам также пришлось бы расширять другие. Таким образом, мы могли бы сократить биты, которые мы используем для представления E, до чего-то меньшего, чем 8 бит, но затем удлинить биты, которые мы используем для представления X, чтобы они были больше 8 бит.
Если бы E и X появлялись с равными частотами, это вообще не сохранило бы никаких данных, потому что сокращение длины битов, которые мы используем для представления E, будет идеально сбалансировано расширением для представления X.
Но в конечном итоге это экономит много данных, потому что E используется намного чаще, чем X, поэтому сокращение количества битов, используемых для представления E, оказывает большее влияние.
Деревья Хаффмана - это алгоритм, используемый для генерации наиболее эффективных битовых кодировок для набора данных. Во многих системах сжатия без потерь используется некоторая вариация Хаффмана.
Распространенные алгоритмы сжатия данных и их применение
За последние несколько десятилетий ученые-компьютерщики разрабатывали и совершенствовали различные алгоритмы сжатия данных. Сегодня используется множество различных алгоритмов, причем некоторые из них более эффективны для видео, а другие - для изображений. Вот некоторые из наиболее распространенных из них:
- LZ77 – Появился в 1977 году, использует тройки для обозначения смещения, количества символов во фразе и маркеров для отклоняющихся символов.
- LZSS – Усовершенствование по сравнению с LZ77, использующее только пары без отклонений. Используется в формате сжатия .rar и для сжатия сетевой информации.
- DEFLATE – метод сжатия данных, объединяющий два предыдущих метода с кодами, назначаемыми на основе частоты символов.
- LZMA – Использует LZ77 на битовом уровне, а затем дополнительно сжимает данные с помощью арифметического кодирования. Чаще всего используется 7-Zip. Формат был обновлен до LZMA2 в 2009 году.
- MLP – Одна из первых нейронных сетей, MLP использует комбинацию двоичного кодирования, квантования и попиксельного преобразования для создания выходных данных.
- RLE – сжатие без потерь, которое сохраняет одно значение в количестве, отлично подходит для сжатия изображений и анимации.
- ZStandard – Еще одно сжатие без потерь. Он похож на DEFLATE, но обеспечивает более быструю декомпрессию и может быть сопряжен со словарем для еще более быстрого сжатия данных.
- bzip2 – Основанный на сжатии сортировки блоков преобразования Берроуза-Уилера, bzip2 ищет повторяющиеся последовательности и преобразует их в одинаковые строки букв. Затем он использует два дополнительных преобразования, приводящих к блокам размером от 100 до 900 КБ.
Преимущества сжатия данных
Основная причина, по которой мы сжимаем наши файлы, заключается в экономии места на диске. Это, в свою очередь, экономит время передачи, использование данных для отправки файлов через интернет, а также аппаратное обеспечение, поскольку нам не нужно много устройств хранения для хранения всех данных. Сжатие также полезно для резервных копий, и многие приложения для предотвращения потери данных будут сжимать ваши резервные копии для более быстрого доступа в дальнейшем.
Однако у сжатия есть один существенный недостаток: повышенные требования к вычислительной мощности. При том, как работает сжатие данных, доступ к сжатым форматам и файлам может быть медленнее, что может привести к заиканию на более медленных машинах, если это делается на лету. Именно по этой причине некоторые алгоритмы и форматы файлов стали более популярными, чем другие.
Как рассчитывается сжатие данных?
Невозможно рассчитать сжатие до завершения процесса и сохранения данных. Кроме того, результаты различаются в зависимости от типа сжимаемых данных. При этом можно рассчитать степень сжатия, разделив размер сжатого файла на исходный размер файла и умножив результат на 100.

Автор этого материала - я - Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML - то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.

 Программы на заказ
Программы на заказ Отзывы
Отзывы Контакты
Контакты